Rocket-Fuelyour Product
UX/UI and Development for
Mobile Apps, Web & Emerging Technologies


From native and hybrid mobile apps for iOS & Android, data-driven full-stack web applications to enterprise-grade software, our Agile mobile app development, full-stack and QA engineers build, test, deploy, and support custom solutions.

With a hands-on approach to design thinking, we identify UX tactics to validate and test design solutions that anticipate a user need or challenge and convert wireframes and prototypes to human-centered pixel-perfect web and mobile end-products.

Our multidisciplinary design and development talent hub allows you to scale and upgrade your team, product, quality and velocity. A senior team of designers, developers and architects works full/part-time in a podular structure and integrates seamlessly with your team, process and workflow.

We harness Blockchain and AI to disrupt Healthcare, Logistics and Fintech. From Smart Contracts for Decentralized Applications to NFT marketplaces, our seasoned team of Blockchain, data scientists and Machine Learning engineers make clients’ products better but oftentimes even possible.

We ensure scalable and safe deployment of the products we build. Among our services we count Pentests, Risk-Based Security Tests, Threat Modeling and Continuous Vulnerability Scanning. December Labs is ISO 27001 certified since 2022.

From software for IoT devices over an embedded OS or RTOS, down to bare-metal firmware, our specialized team can provide specific development services as well as integrate with other areas of the company to provide an end-to-end product development service.








































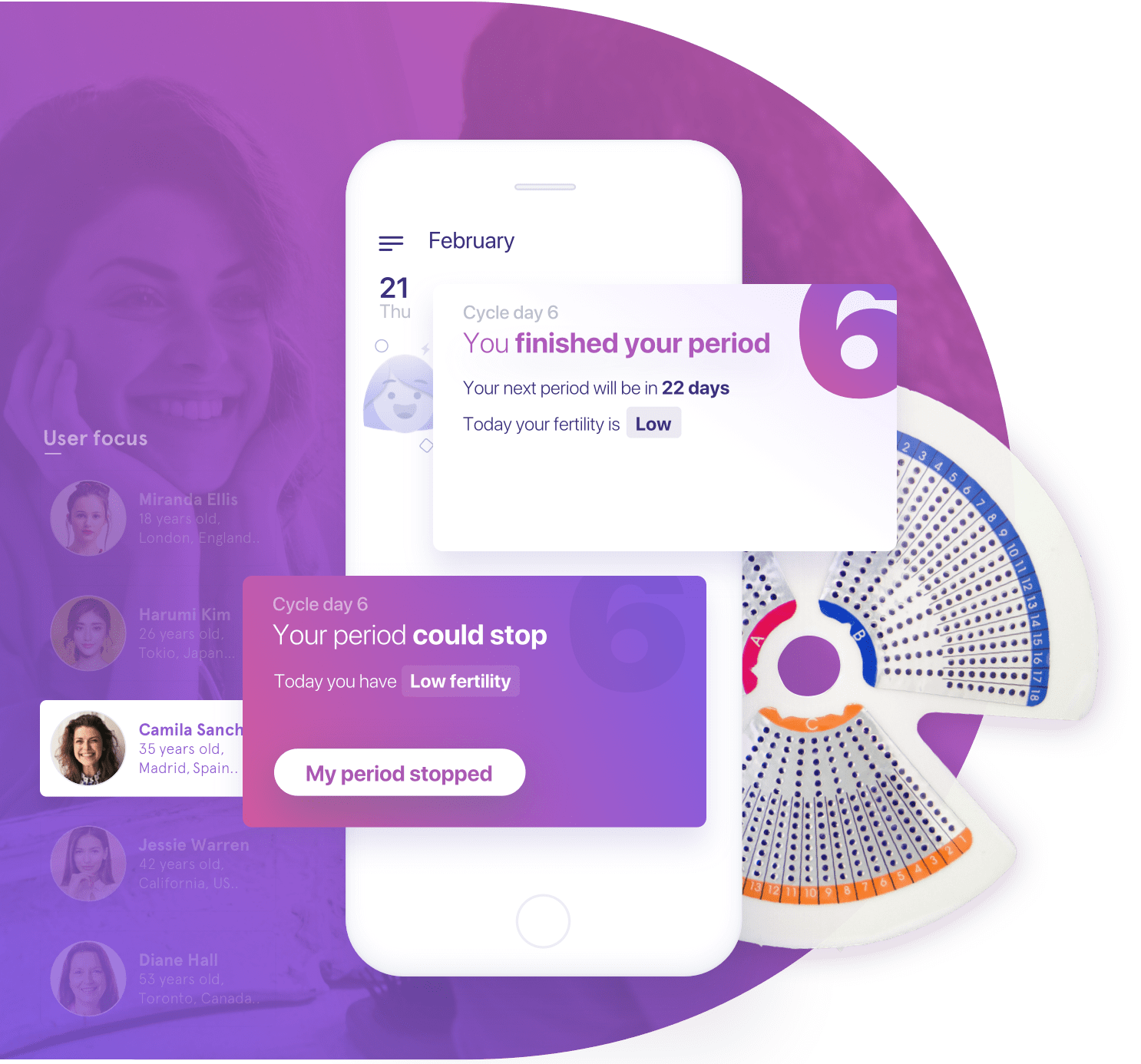
Case Study
Our HIPAA-compliance experience, AI and Computer Vision know-how and high sense of product ownership, made December Labs a perfect match for Welwaze Medical to build their Celbrea App, featuring a mapping device, an app with advanced dynamic AI algorithms and Blockchain Technology.
Continue to case study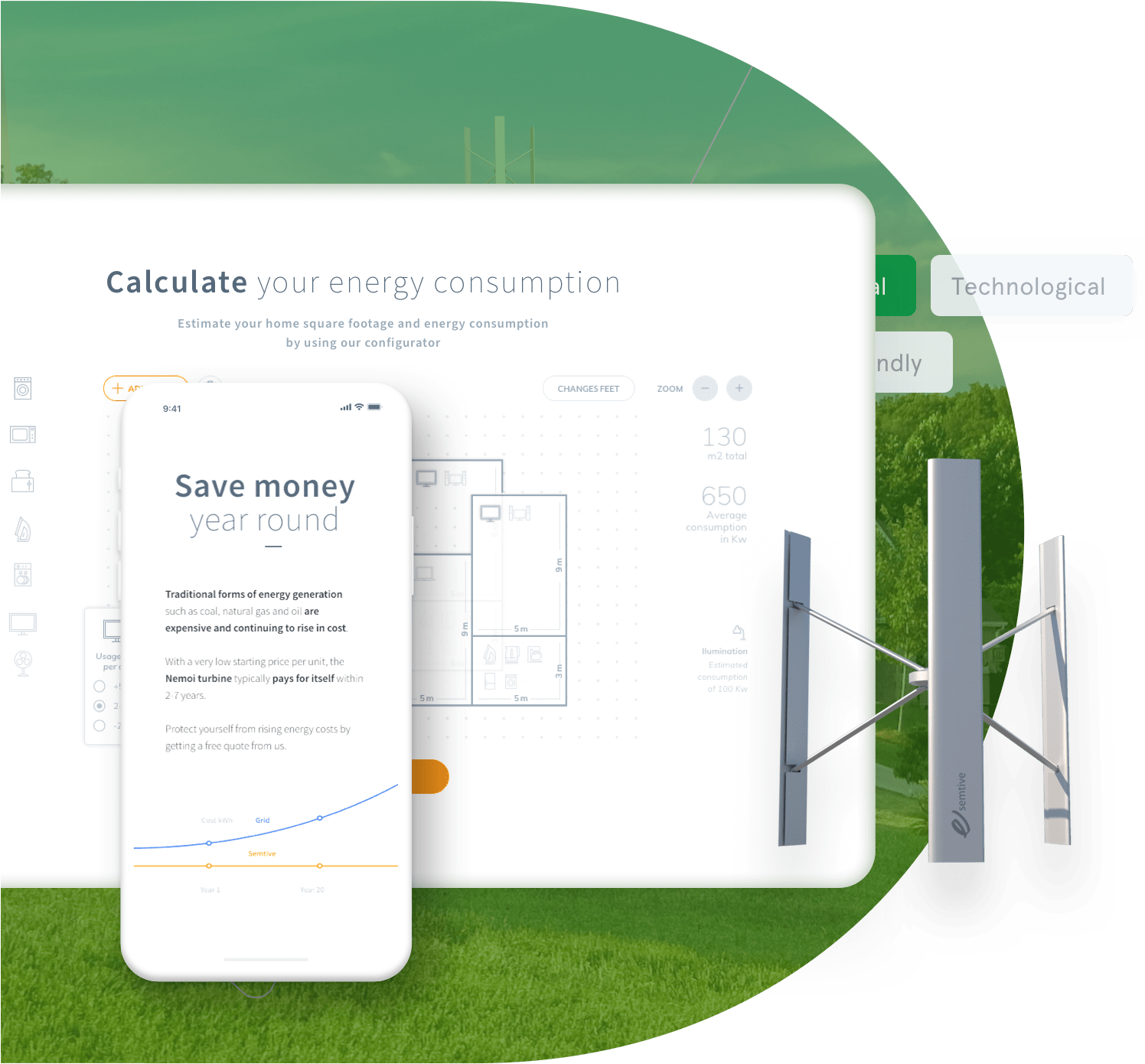
Case Study
We transformed a complex purchase decision-making process into an intuitive and valuable user experience by developing an integrated webapp calculator to determine individual energy consumption.
Continue to case study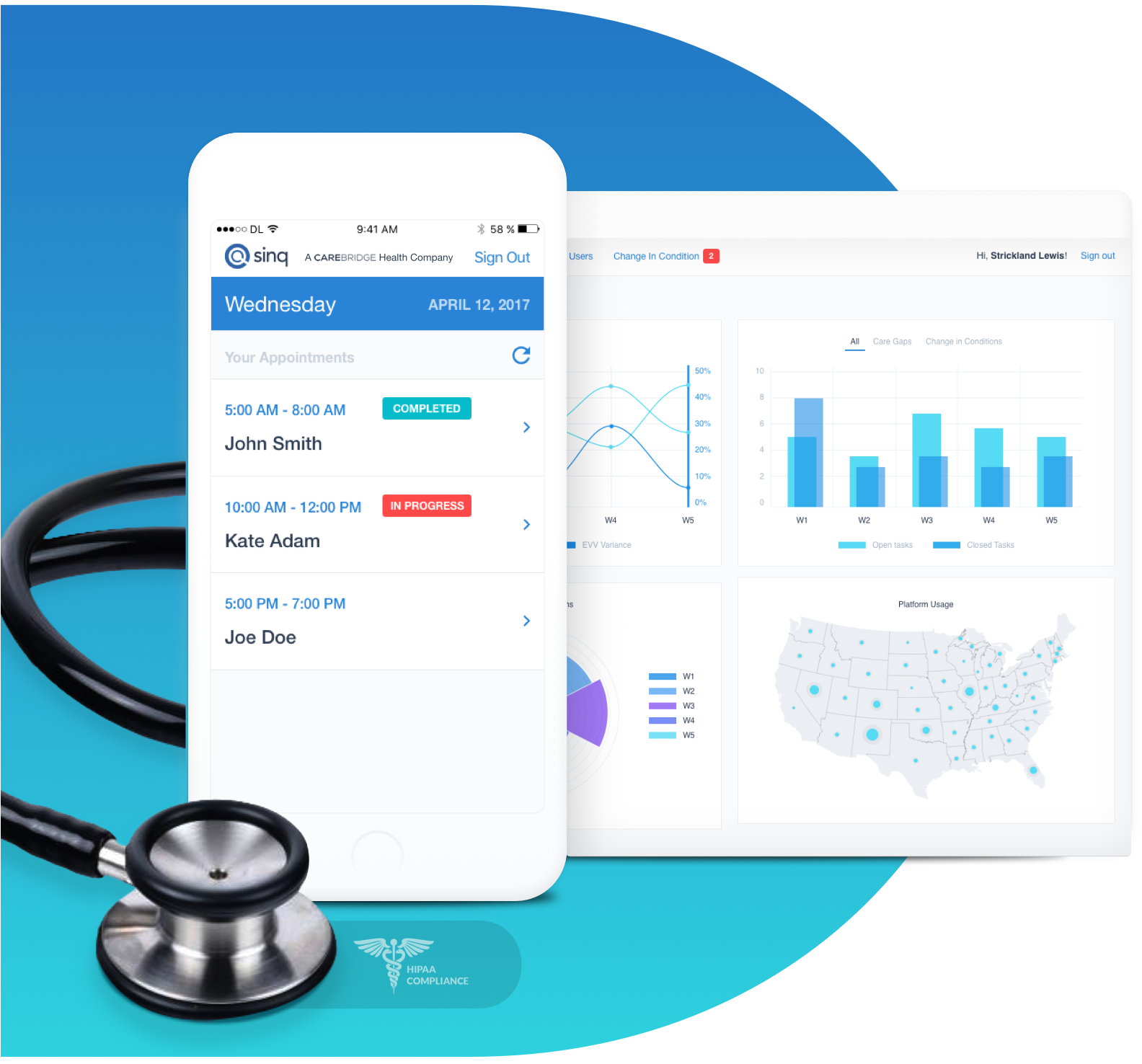
Case Study
The HIPAA-compliant integrated cloud and mobile-first platform we built for SinQ technology provides a largely untapped potential source of insight into @home care delivery for health plans and care providers.
Continue to case study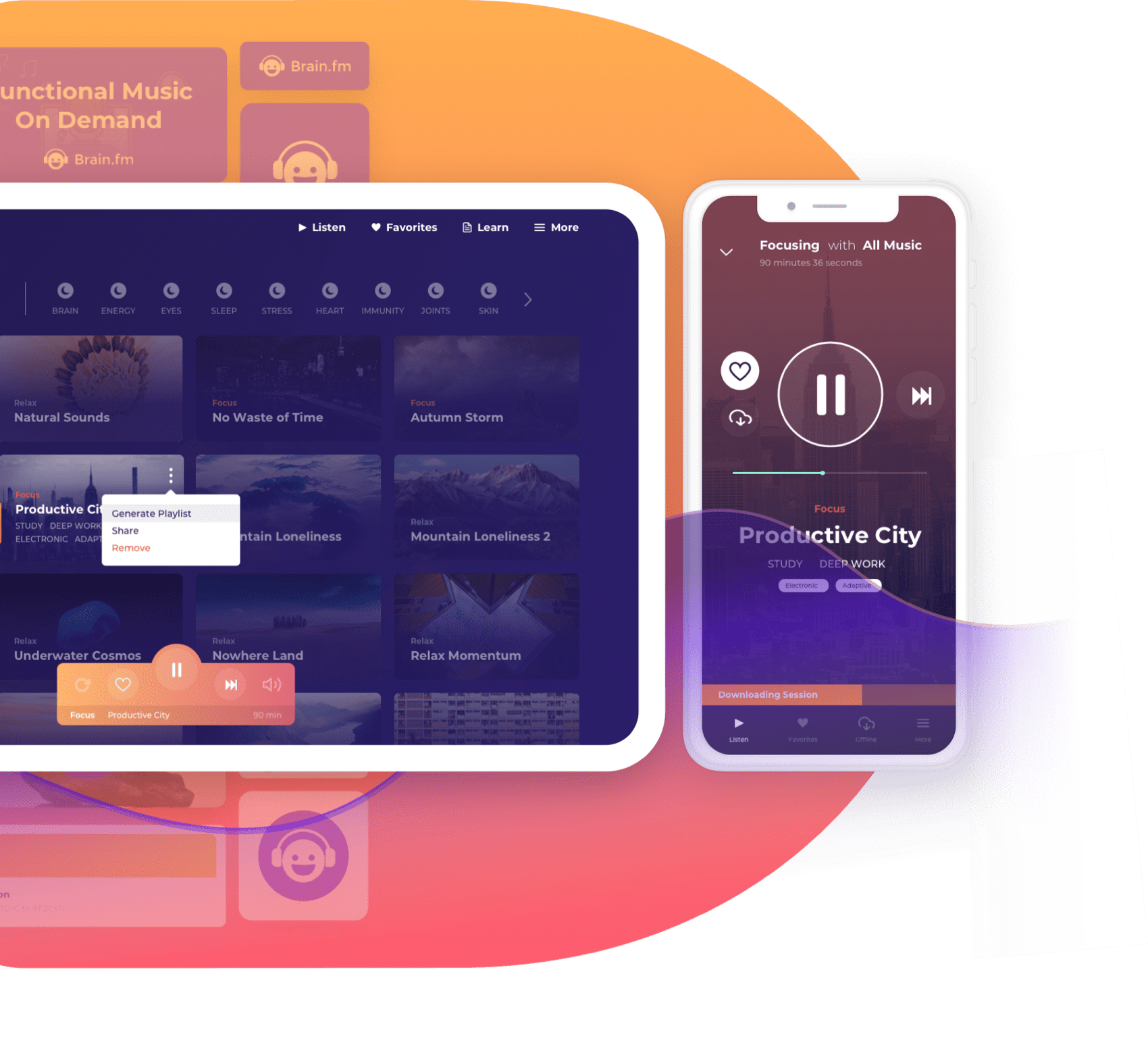
Case Study
From a complete makeover to building Brain.fm’s MacOS desktop app, we positioned the design thinking process at the core of our approach by applying tactics such as color psychology and natural language.
Continue to case study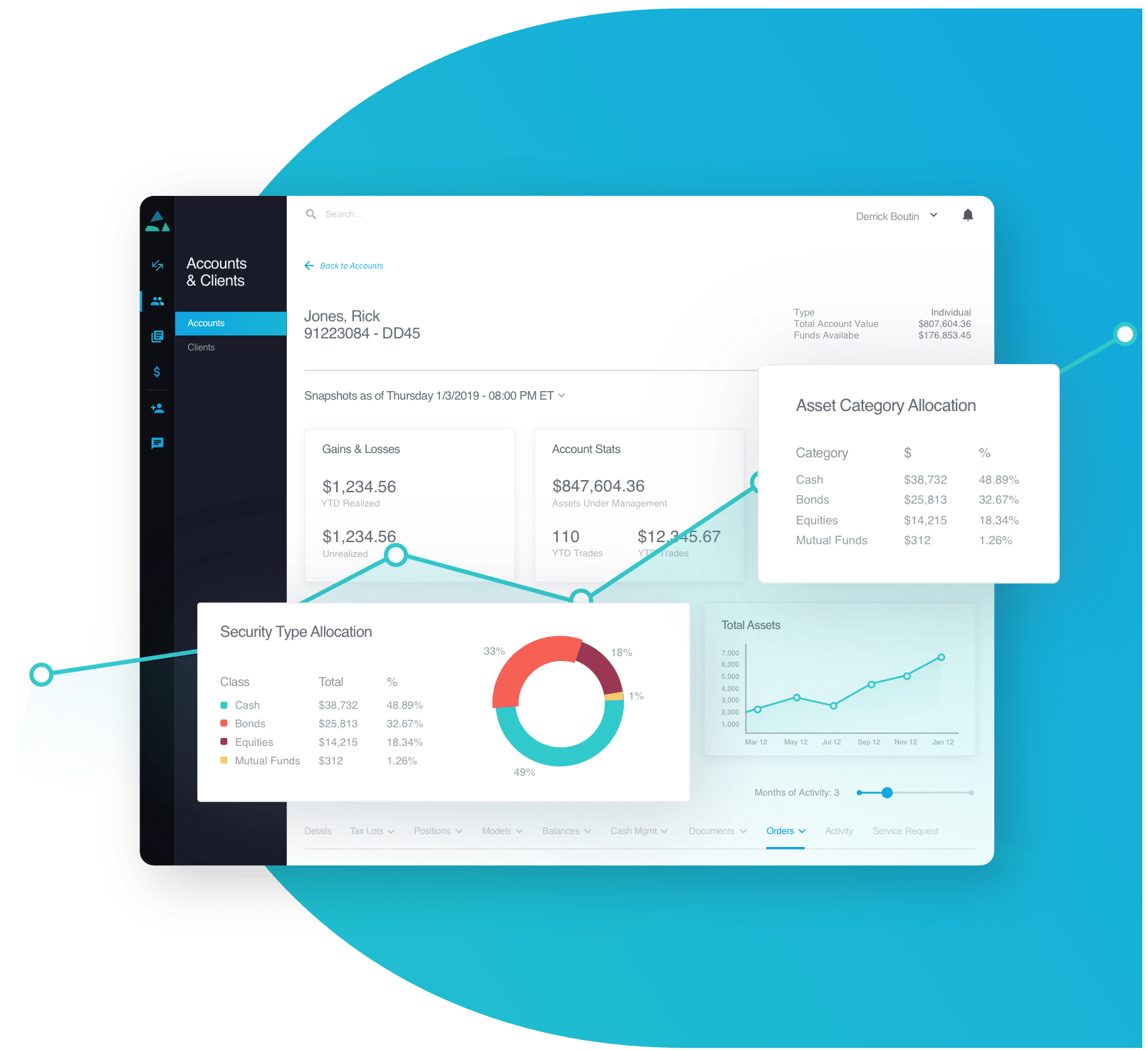
Case Study
Leveraging December Labs' proven experience in the finance vertical, TradePMR approached us for a UX-driven makeover of their sophisticated and complex WebApp advisor workstation and cloud-based mobile solution Earnwise.
Continue to case study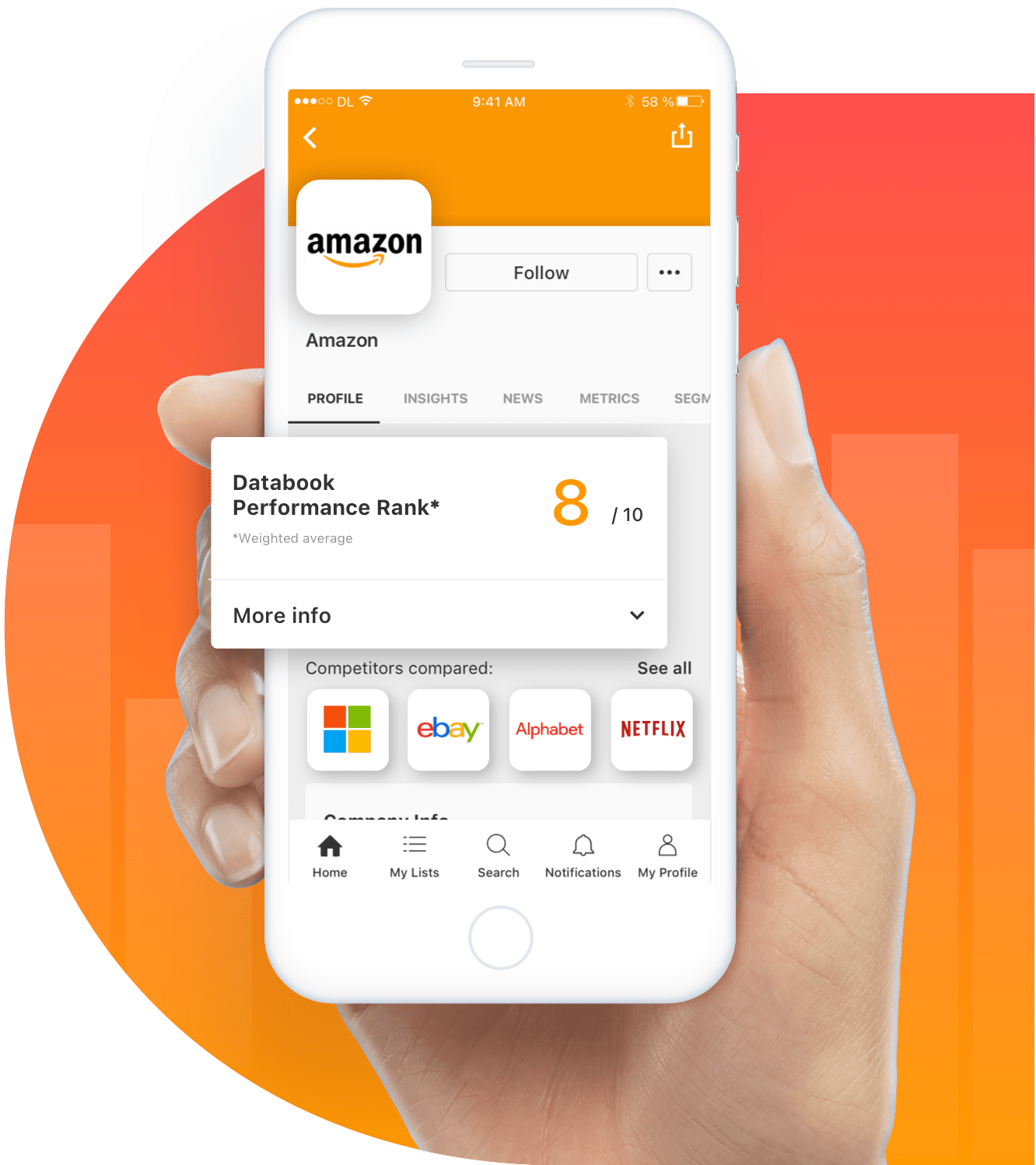
Case Study
Bringing together industry, technology and design expertise, Databook partnered with December Labs for a mobile-first value approach to B2B sales.
Continue to case study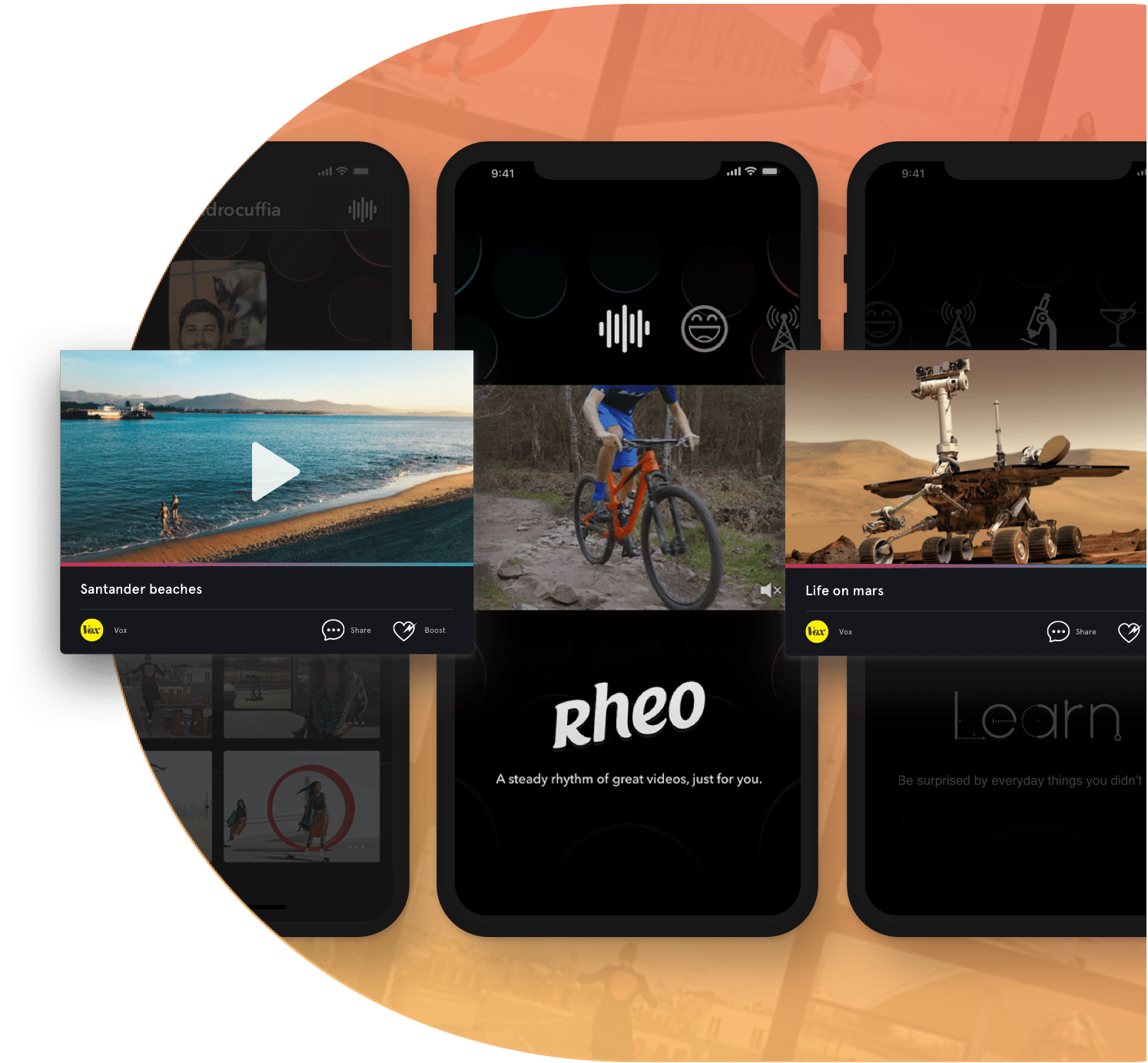
Case Study
December Labs partnered with Rheo to develop an original and powerful iOS app used by over a million users and featured as one of the best apps of the App Store.
Continue to case study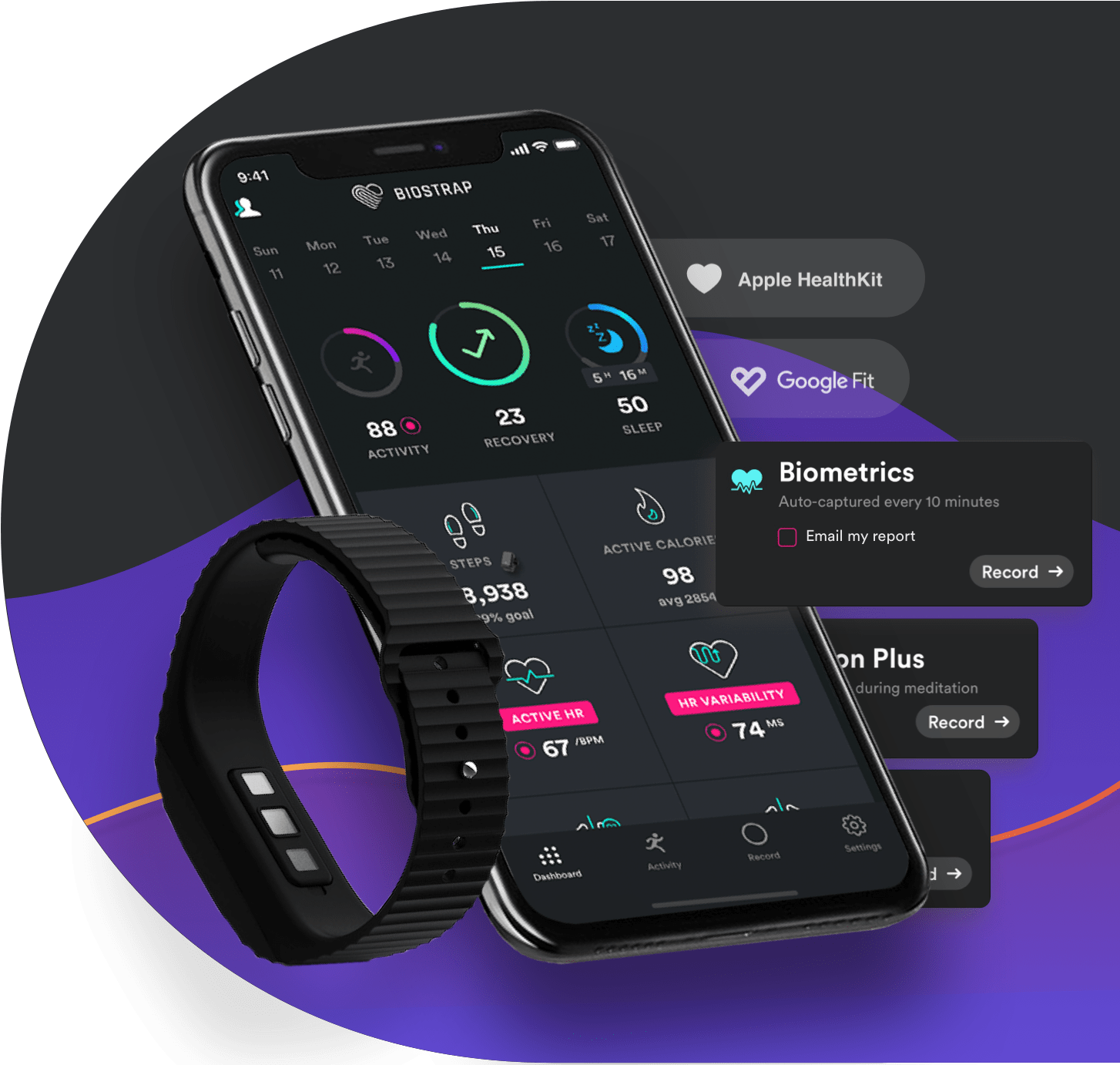
Case Study
For the past 4 years, we have been driving the Biostrap platform, featuring dual-device wearable technology (wristband and shoe pod), oxygen saturation, heart rate variability measurements and machine-learning integrations.
Continue to case study